

Most SEO problems don’t come from what you see on your website.
They come from what Googlebot fails to see.
I’ve personally seen pages that looked perfect to users. But for Google, the main content was missing, broken, or completely invisible.
Result?
Crawled… but not indexed
Indexed… but never ranked
This is where “View Page as Googlebot” becomes critical.
In this blog, you won’t just learn what Googlebot is? You’ll learn how to actually diagnose and fix real crawling & rendering issues using Google’s own perspective.
New to SEO overall? This beginner’s guide covers the fundamentals first.
Why Pages Get Crawled But Not Indexed
Before understanding Googlebot, you need to understand this:
Google doesn’t index pages just because it can crawl them.
Here are the real reasons I’ve seen behind “Crawled – currently not indexed”:
- Content exists but adds no new value
- Important content loads via JavaScript but fails to render
- Key resources (CSS/JS) are blocked in robots.txt
- Page looks thin or incomplete to Googlebot
- Internal linking is too weak to signal importance
Key Insight: If Googlebot doesn’t see enough value → it quietly drops your page.
What “View Page as Googlebot” Actually Means
“View Page as Googlebot” means: Seeing your page exactly how Google renders it, not how users see it.
Because your browser:
- executes everything perfectly
- loads all resources
But Googlebot:
- depends on allowed resources
- renders in stages
- may miss critical content
Think of Googlebot as a super-advanced browser that visits your website but with a very specific purpose: understanding content for search indexing, not for human browsing.
Do you know? Search engines don’t use just one crawler. The most important ones are:
- Googlebot Smartphone – Primary crawler
- Googlebot Desktop – Used in some cases
- Googlebot Image – Crawls images
- Googlebot Video – Crawls video content
This means Google may look at different parts of your site depending on the content type.
How to Actually View Your Page as Googlebot (Step-by-Step)
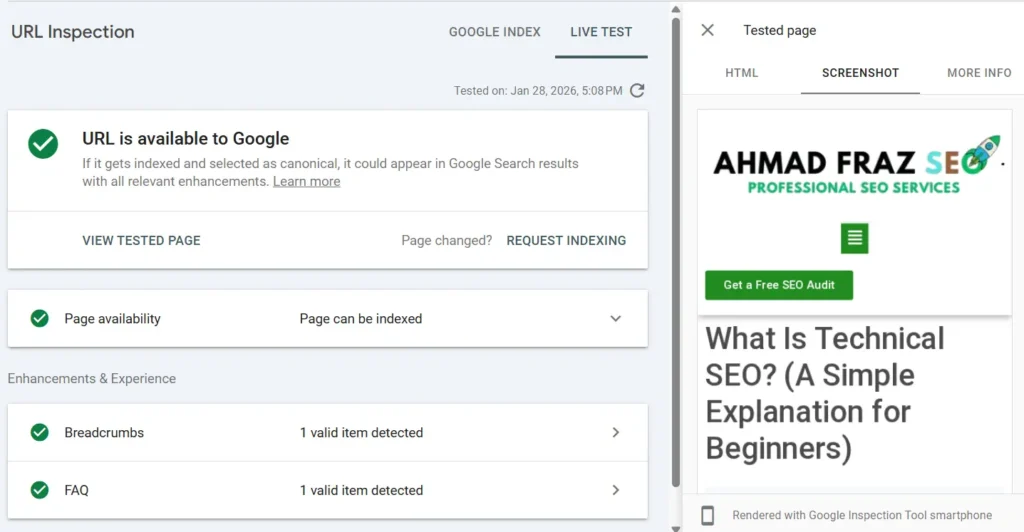
Use Google Search Console
- Open Google Search Console
- Paste your URL in URL Inspection Tool
- Click “Test Live URL”
- Open “View Tested Page”
Now check 3 things carefully:
1. Screenshot
Does it match your real page?
- Missing sections? → rendering issue
- Broken layout? → CSS blocked
- Empty content? → JS issue
2. HTML Output
Check if your main content exists in raw HTML
If NOT: Google may not index it
3. Blocked Resources
Look for:
JS blocked
CSS blocked
These directly affect visibility.
If you have confusion between crawling and indexing, you can read what is the difference between crawlability and indexability.”
Real Case Example
Once I audited a page where:
- Content was loaded via JavaScript
- robots.txt blocked
/js/
For users → page looked perfect
For Googlebot → page looked EMPTY
Result: Not indexed
After:
unblocking JS
re-requesting indexing
Page got indexed within days.
How Googlebot Actually Processes Your Page
Before your page appears in search results, Googlebot goes through a structured process to understand it. If something breaks at any step, your page may not get indexed or ranked.
Here’s how it works:
- Discovery – Googlebot finds your URL through links, sitemaps, or previously indexed pages
- Crawling – It requests your page and downloads the HTML and resources
- Rendering – It processes JavaScript and builds the final version of the page
- Evaluation – It analyzes content, structure, and signals
- Indexing Decision – It decides whether your page deserves to be indexed or ignored
Common Googlebot Problems (With Fixes)
Even well-designed pages can fail in search if Googlebot can’t properly access or understand them. Most indexing issues come from small technical gaps that are easy to miss but critical to fix.
Here are the most common problems and what they actually mean:
- JavaScript blocked – Google sees empty or missing content → Allow JS files in robots.txt
- CSS blocked – Layout breaks during rendering → Allow CSS files
- noindex present – Page is intentionally excluded → Remove the tag if indexing is needed
- Weak internal linking – Page looks unimportant → Add contextual internal links
- Thin or generic content – Low perceived value → Improve depth and uniqueness
Let’s make it easy to understand in the tabular form.
| Problem | What Google Sees | Fix |
|---|---|---|
| JS blocked | Empty content | Allow JS |
| CSS blocked | Broken layout | Allow CSS |
| noindex tag | Page excluded | Remove tag |
| Weak internal links | Low importance | Add links |
| Thin content | Low value | Improve depth |
Advanced Insight: Why Googlebot Is Not the Same as Browser (Googlebot ≠ Browser)
Many people assume Googlebot sees pages exactly like a normal browser, but that’s not true. This misunderstanding is one of the biggest causes of hidden SEO issues.
Here’s how Googlebot actually differs:
- Delayed rendering – JavaScript isn’t always processed instantly
- Resource prioritization – Heavy scripts may be skipped or delayed
- Dependency sensitivity – Blocked files can break the entire page view
- Efficiency-first behavior – It doesn’t “wait” like a real user browser
Result: A page that looks perfect to users can still appear broken to Google.
Best Practices to Ensure Googlebot Can Fully Crawl, Render, and Index Your Pages
To avoid crawling and indexing issues, you need to optimize your pages specifically for how Googlebot accesses and processes content not just how users see it.
Follow these essential practices:
- Keep critical content in HTML – Don’t rely fully on JavaScript
- Allow CSS and JS files – Avoid blocking key resources in robots.txt
- Use strong internal linking – Help Google understand page importance
- Test pages regularly – Use Search Console’s URL Inspection tool
- Avoid unnecessary complexity – Simpler pages are easier to process
FAQ - Googlebot & View Page as Googlebot
Googlebot is Google’s web crawler that discovers and indexes web pages for search results.
It helps you see rendering issues, blocked resources, and indexing problems from Google’s perspective.
No. It only controls crawling. Use noindex to stop indexing.
It’s the identifier string Googlebot sends when requesting a webpage.
Yes, using Search Console’s Live Test and server log analysis.
Google renders JS, but delays or blocked resources can cause indexing issues.
Googlebot uses Google-owned IP ranges that can be verified via reverse DNS.
One crawls images, the other understands video content and metadata.
Final Thoughts
Understanding how Googlebot works is one of the most powerful skills in technical SEO.
When you “view a page as Googlebot,” you stop guessing and start seeing your site the way Google does. That’s how you uncover hidden SEO problems that competitors miss.
If you want better rankings, make sure:
- Googlebot can crawl your pages
- It can render your content
- It’s not blocked by robots.txt or noindex
- Your images, videos, and JS are accessible
Sometimes the problem isn’t obvious, and a small technical gap can quietly block your entire page from ranking.
If you’re stuck with indexing issues or something just doesn’t make sense… Ahmad Fraz SEO has been there. Just get technical audit for your site today!
Ahmad Fraz is a seasoned SEO strategist and digital marketing expert with over 9 years of experience helping brands like Dyson, 3M, Marriott, and CureMD achieve measurable growth. Specializing in technical SEO, content strategy, and data-driven optimization, at Ahmad Fraz SEO, he empowers businesses of all sizes to improve visibility, drive qualified traffic, and achieve long-term digital success. His insights and actionable strategies are backed by years of hands-on experience and proven results.