
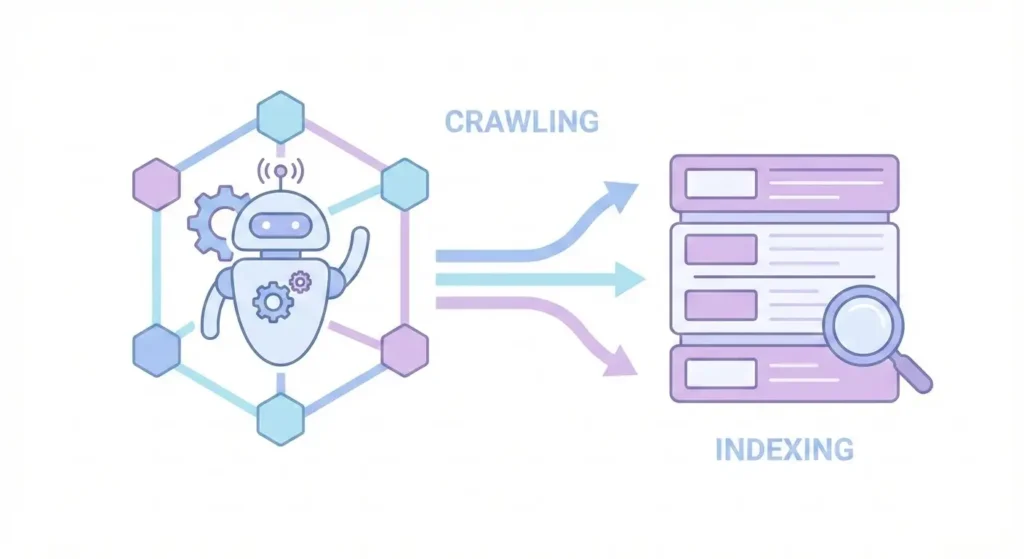
In technical SEO, two terms get mixed up all the time, crawlability and indexability.
They sound similar.
They happen close together.
But they are not the same thing.
And here’s the problem: if you don’t understand the difference, you might fix the wrong issue and still wonder why your page isn’t showing up in Google.
Let’s clear this up once and for all.
What Is Crawlability?
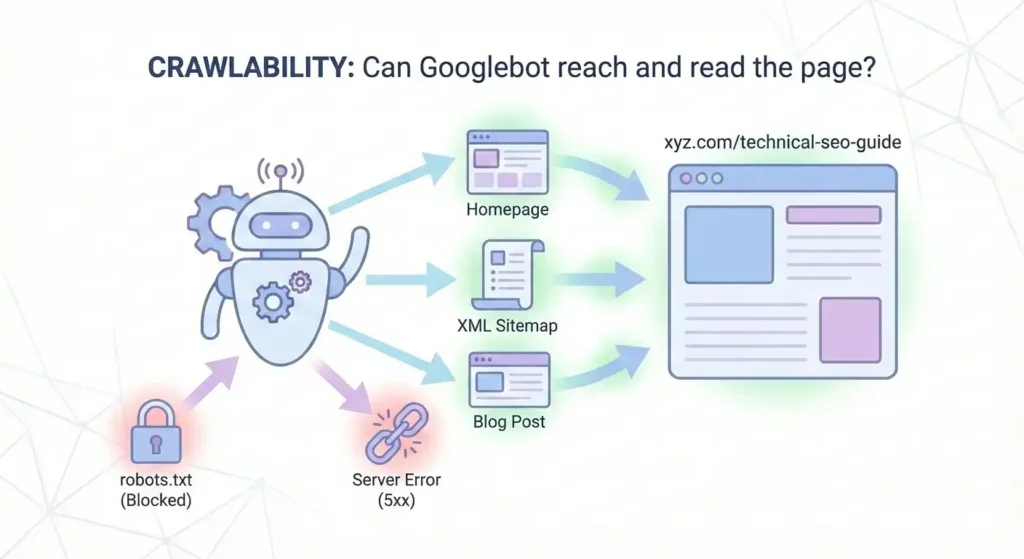
Crawlability refers to a search engine’s ability to discover and access pages on your website.
Before Google can rank anything, its bots (like Googlebot) must first crawl your pages meaning they visit the URL and read the content.
If a page isn’t crawlable, Google can’t even see it.
Simple Example
Imagine you have a website: xyz.com
You publish a new page: xyz.com/technical-seo-guide
Now Google needs to find and access this page.
That can happen through:
- A link from your homepage
- A blog post linking to it
- Your XML sitemap
- An external backlink
If Googlebot can reach the page and load it successfully, your page is crawlable.
But if:
- The page is blocked in robots.txt, or
- There are no internal links pointing to it (orphan page), or
- The page returns a server error (5xx)
Then Google can’t properly access it, meaning the page has a crawlability issue.
So in this example, crawlability simply means:
Can Googlebot reach and read xyz.com/technical-seo-guide?
What Affects Crawlability?
Several technical elements control whether search engines can crawl your site:
- Internal links – Pages with no links pointing to them (orphan pages) are hard to find
- Robots.txt file – Can block search engines from accessing certain pages
- Site structure – Poor navigation makes crawling inefficient (this is closely tied to crawl depth, how many clicks it takes to reach a page from your homepage)
- Redirect chains & loops – Waste crawl budget (For the full picture on redirect types and when to use each one, see SEO redirects.)
- Broken links and 404 errors – (See broken links in SEO for the full breakdown)
- Server errors (5xx) – Stop bots from accessing pages
- XML sitemaps – Help search engines discover important URLs
Think of crawlability as Google being able to enter your house and walk through the rooms.
If the doors are locked, crawling stops right there.
What Is Indexability?
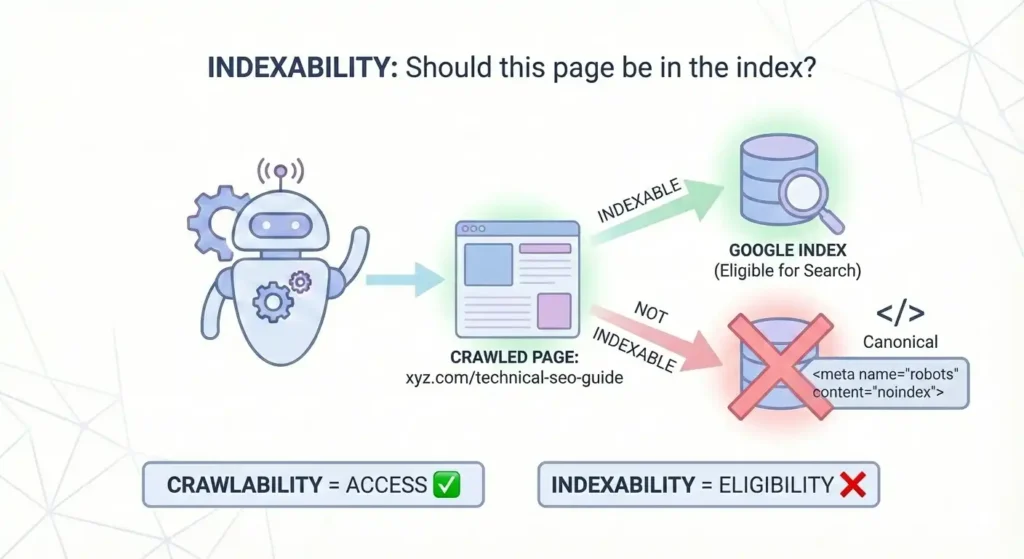
Once Google successfully crawls xyz.com/technical-seo-guide, the next step is deciding:
“Should we store this page in our index and show it in search results?”
That decision is called indexability.
So while crawlability is about access, indexability is about eligibility to appear in Google search.
Continuing the Same Example
Let’s say Googlebot was able to crawl: xyz.com/technical-seo-guide
But the page has this tag in the code:
<meta name=”robots” content=”noindex”>
Now what happens?
Google can see the page, but it is instructed not to include it in the index.
So:
- The page is crawlable ✅
- But it is not indexable ❌
Another case:
If the page has a canonical tag pointing to another URL, Google may choose to index the other page instead.
👉 In simple words:
Crawlability = Google can visit the page
Indexability = Google is allowed (and willing) to show it in search results
Crawlability vs Indexability (Quick Comparison)
Here’s the difference in a simple table:
Feature | Crawlability | Indexability |
What it means | Can search engines access the page? | Can search engines add the page to their index? |
Happens first? | ✅ Yes | ❌ No, it happens after crawling |
Controlled by | Robots.txt, internal links, server status, site structure | Meta robots tags, canonicals, content quality |
Main goal | Let bots reach your content | Let your content appear in search results |
Common issue | Page blocked in robots.txt | Page has a noindex tag |
If this fails | Google never sees the page | Google sees it but won’t rank it |
How Google Crawls and Indexes a Page (Step-by-Step)
Understanding the process makes everything clearer:
Discovery
Google finds a URL through:
- Internal links
- Backlinks
- XML sitemaps
Crawling
Googlebot visits the page and reads:
- HTML
- Content
- Links
- Technical signals
If blocked here → crawlability issue
Indexing
Google analyzes the page and decides whether to include it in its database.
If excluded here → indexability issue
Ranking
Only indexed pages can compete in search results.
Important: Ranking problems are different from crawl or index problems.
Common Crawlability Problems (and Fixes)
Problem | Why It Happens | Fix |
Blocked by robots.txt | Disallowed rule | Update robots.txt |
Orphan pages | No internal links | Add contextual internal links |
Broken links | 404 errors | Fix or redirect URLs |
Redirect chains | Too many hops | Use direct redirects |
Server errors | Hosting issues | Improve server stability |
Common Indexability Problems (and Fixes)
Problem | Why It Happens | Fix |
noindex tag present | Intentional or accidental | Remove if page should rank |
Wrong canonical tag | Points to another URL | Fix canonical reference |
Duplicate content | Multiple similar pages | Consolidate or canonicalize |
Thin content | Low value for users | Improve content depth |
Soft 404 | Page looks like error page | Add real content or return 404 |
Why This Difference Matters for SEO
Here’s the key takeaway:
A page must be
Crawlable → Indexable → Valuable
before it can rank.
You can build amazing content, but if Google can’t crawl it, you’re invisible.
And if Google crawls it but decides not to index it, you’re still invisible.
Technical SEO is often about removing these invisible barriers.
For a deeper, more advanced look at fixing crawlability at scale, including log file analysis and JavaScript rendering issues, see this advanced website crawlability guide.”
Frequently Asked Questions (FAQs)
Yes. This happens often. Google can access the page, but a noindex tag, canonical tag, or quality issue prevents it from being added to the index.
No. If Google can’t crawl a page, it can’t index it. Crawling always comes first.
No. A sitemap helps with discovery (crawlability), but Google still decides whether the page is worth indexing.
Use tools like:
- Google Search Console (URL Inspection Tool)
- Screaming Frog
- Sitebulb
- Ahrefs Site Audit
Yes. Crawl budget affects how often and how deeply Google crawls your site, especially for large websites
SEO Isn’t Just About Google (Even If It Feels Like It)
StatsCounter Global Stats says: “Around 85% of people in the U.S. use Google for search. But that still leaves millions of searches happening every day on other platforms like Bing, Yahoo, and DuckDuckGo.“
And guess what? They all crawl and index websites too.
Just like Google uses Googlebot, other search engines have their own crawlers:
- Bing uses Bingbot to discover and analyze pages across the web
- Yahoo largely relies on Bing’s search technology
- DuckDuckGo combines results from partners like Bing along with its own crawler, DuckDuckBot, while focusing heavily on user privacy
The core process is still the same:
Discover → Crawl → Index → Rank
But each search engine has its own algorithm and ranking signals. That means a technically sound site — one that is crawlable and indexable — doesn’t just perform better on Google. It becomes more visible across the entire search ecosystem.
So while Google may be the giant, smart SEO is about making your website accessible to all search engines, not just one.
After all, visibility anywhere in search is still visibility.
Quick question before you go:
Do you stick with Google for everything, or do you sometimes use another search engine or browser?
Ready to Boost Your Website’s SEO?
If you want crawlable, indexable, and fully optimized pages that actually rank on Google and other search engines, I can help. I specialize in technical SEO audits, on-page optimization, and site structure improvements that get results.
Let’s make your website SEO-proof and Google-friendly.
Contact Ahmad Fraz SEO and get your site ranking higher with expert technical SEO services!
Ahmad Fraz is a seasoned SEO strategist and digital marketing expert with over 9 years of experience helping brands like Dyson, 3M, Marriott, and CureMD achieve measurable growth. Specializing in technical SEO, content strategy, and data-driven optimization, at Ahmad Fraz SEO, he empowers businesses of all sizes to improve visibility, drive qualified traffic, and achieve long-term digital success. His insights and actionable strategies are backed by years of hands-on experience and proven results.